深入理解LoRA:原理、训练及如何应用
AI 大模型 生成式AI
LoRA的定义和核心应用
低秩自适应(LoRA)技术,作为一种先进的模型微调方法,正因其在降低模型复杂性、减少资源消耗的同时保持高性能,而受到越来越多的关注。在人工智能领域,优化模型的效率和性能是研究人员和工程师们持续追求的目标。
LoRA技术的核心在于利用低维结构来近似高维的模型参数,从而实现模型的低秩化。这种方法能够有效地减少模型的参数数量,进而降低模型的存储需求和计算复杂度,而又不牺牲模型的性能。在实际应用中,LoRA通常被用于微调预训练的大模型(LLM),通过在模型的某些关键矩阵旁插入低秩矩阵,实现对模型的定制优化,以适应特定的任务或领域。
LoRA原理:高效优化模型结构
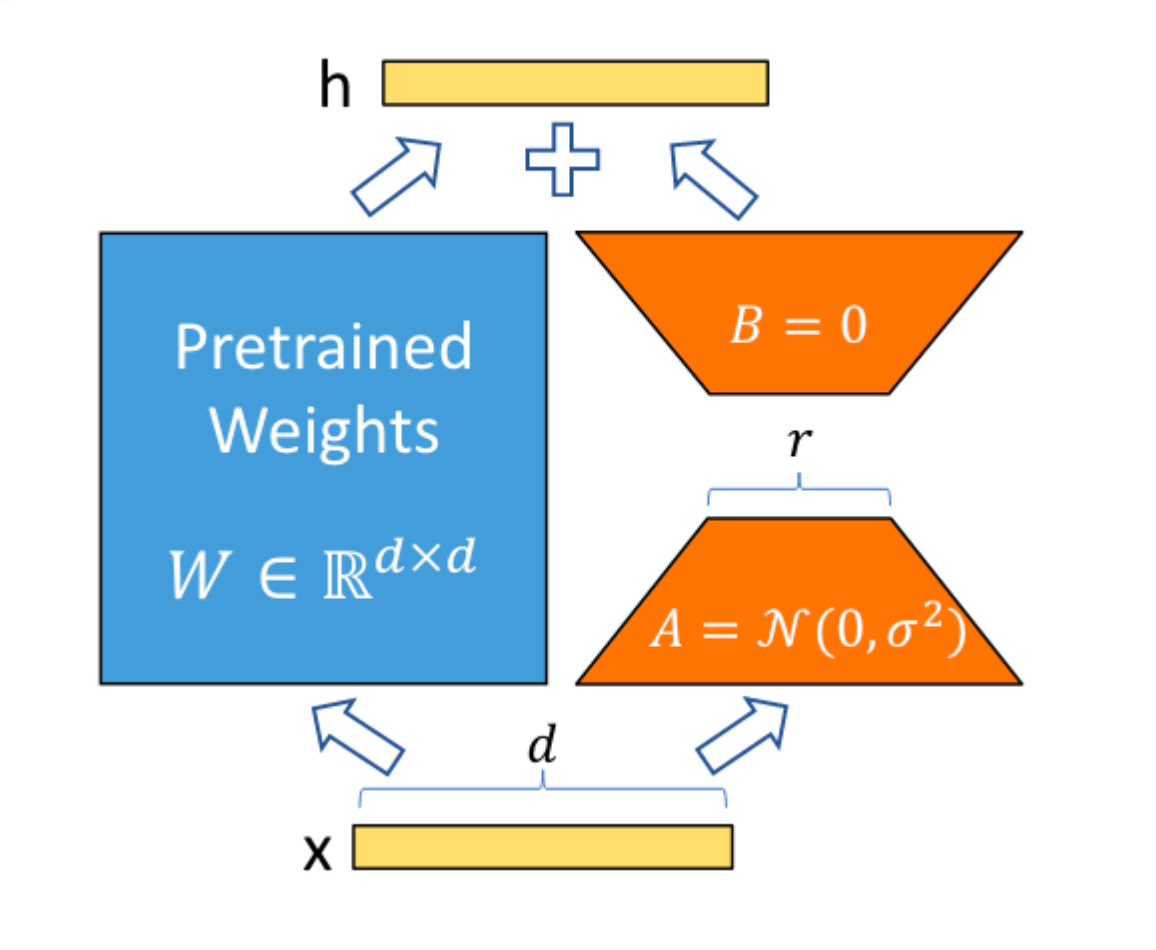
LoRA技术的工作原理建立在矩阵分解和近似的基础之上。具体来说,它通过在模型的特定矩阵旁插入一个并行的新权值矩阵,然后将这个新矩阵分解为两个低维矩阵——降维矩阵A和升维矩阵B,从而达到减少模型参数数量的目的。这里的关键在于利用了模型的低秩性,即模型中实际上只有一小部分参数对特定任务或模式的响应是显著的。
在LoRA中,降维矩阵A的列数通常远小于原矩阵的列数,而升维矩阵B的行数也远小于原矩阵的行数。这意味着,通过这种分解,原矩阵的大部分信息被压缩到了一个小得多的子空间中。在实际训练过程中,保持预训练模型的参数固定不变,只优化A和B这两个低秩矩阵,从而大幅降低了训练的计算量。
在模型训练完成之后,LoRA通过将A和B合并加到原参数上来调整模型的行为。这种合并操作是线性的,不会在推理时引入额外的延迟。这是因为在实际部署时,可以将A和B当作新的模型参数直接加入到原有模型中,无需在推理过程中进行额外的计算。这种设计在保持模型原有性能的同时,显著提升了训练效率,并有效地控制了模型的存储需求。

LoRA实现:初始化与参数调优
在LoRA技术的实际实现过程中,有几个关键的细节对于模型的性能至关重要。首先是矩阵的初始化策略,LoRA要求降维矩阵A使用高斯分布进行初始化,而升维矩阵B则使用零矩阵进行初始化。这种初始化方式的目的在于保证模型在开始训练时能够保持与预训练模型相同的行为,从而在训练初期就能获得良好的效果。
为了进一步提升LoRA的性能和适用性,一个名为α的缩放参数被引入到LoRA的实现中。α参数的作用是在改变降维矩阵A的维度r时,减少对超参数进行重新调整的需要。通过合理设置α的值,可以在不同维度的A矩阵之间实现平滑的过渡,从而优化模型的训练过程。
在训练LoRA时,一个重要的考虑是其对硬件资源的要求。由于LoRA仅需优化低秩矩阵A和B,而不是整个模型,因此它对计算和内存的需求远低于全参数微调。LoRA的设计允许在使用自适应优化器时,进一步提高训练效率,并显著降低硬件进入障碍,这是因为LoRA不需要计算梯度或维护大量参数的优化器状态,只需优化相对较小的低秩矩阵。
LoRA应用:多场景下的灵活部署
LoRA技术的应用场景广泛,尤其在自然语言处理(NLP)领域中的Transformer模型上表现突出。实验表明,通过在Transformer的不同矩阵上应用LoRA,可以实现不同的优化效果。例如,将LoRA应用于自注意力机制中的Wq和Wv矩阵,可以帮助模型更有效地捕捉输入序列的关键信息,从而提高模型的性能。
在多任务学习场景中,LoRA展现了其灵活性和高效性。通过共享一个预训练的模型,并在不同任务之间切换时仅替换LoRA的矩阵A和B,可以显著降低存储需求和任务切换的开销。这种方法允许模型根据具体的任务需求进行快速调整,而无需重新训练整个模型。
具体到部署阶段,LoRA的设计确保了在推理时不会增加额外的延迟。由于训练后的A和B矩阵可以直接合并到原模型参数中,因此在进行推理时,模型可以像全参数模型一样直接处理输入,无需进行额外的计算。这一点对于那些对延迟有严格要求的应用至关重要,比如实时语音识别或在线机器翻译服务。
LoRA优势:高效存储与快速推理
LoRA技术在多个方面展现了其技术优势。
- 在存储需求方面,通过低秩矩阵的引入,LoRA显著降低了模型的参数数量,从而减少了模型的存储要求。这一点对于资源受限的环境或者需要部署多个模型的场景尤为重要。
- 在训练效率方面,LoRA的训练过程远比全参数微调高效。由于LoRA仅需训练模型的低秩部分,即降维矩阵A和升维矩阵B,因此它在训练时的计算量大幅降低。此外,由于不需要维护大量参数的优化器状态,LoRA在使用自适应优化器时能够进一步提升训练效率。
- 推理延迟方面,LoRA的设计确保了在推理时不会引入额外的延迟。在模型训练完成后,低秩矩阵A和B可以直接加到原参数上,合并后的模型与完全微调的模型在推理时的效率相当。这种线性合并的设计简化了部署流程,并保持了与原始模型相同的推理速度。
LoRA技术不仅在理论上具有显著的优势,而且在实际应用中也证明了其有效性。它为深度学习模型提供了一种高效的压缩和优化方法,特别是对于需要在性能、存储和速度之间寻求平衡的应用场景。
实战LoRA:BetterYeah AI Agent的应用
在实际应用中,LoRA技术已被成功部署于多个AI平台和产品中,其中BetterYeah AI Agent平台是一个突出的例子。这是一个一站式的智能体开发平台,集成了国内外的主流大模型,提供了从模型选择、微调到部署的全流程支持。用户可以在BetterYeah平台上根据具体的应用场景选择合适的模型,并通过LoRA技术进行快速的模型微调,以适应特定的任务需求。
在BetterYeah AI Agent中,LoRA微调的模型能够有效地处理多模态智能问答任务,这得益于LoRA在降低模型复杂性和提升训练效率方面的显著能力。通过LoRA微调,平台能够在保持高性能的同时,显著减少模型的存储需求和推理延迟,这对于需要快速响应和处理大量请求的智能问答系统尤为重要。
立即访问BetterYeah AI Agent官网,体验行业AI成功应用案例。

LoRA技术的未来趋势
LoRA技术自提出以来,已经引起了学术界和工业界的广泛关注。当前的研究表明,LoRA不仅能够有效降低模型的参数数量和复杂性,还能提高模型在特定任务上的性能。在边缘设备上,LoRA的应用更是展现了其在资源受限环境下的优越性,成为AI技术在边缘计算领域的一个重要突破。
未来,随着人工智能技术的不断进步和边缘计算需求的日益增长,LoRA技术有望在更多的应用场景中得到验证和应用。特别是在智能客服、智能制造、医疗健康等领域,LoRA的技术优势有望为这些领域的智能化提供强有力的支持。随着LoRA技术的深入研究,其理论基础和应用方法将进一步完善。例如,未来研究可能会探索LoRA在动态环境适应性和模型鲁棒性方面的表现,以及如何将LoRA与其他先进的AI技术相结合,以实现更加智能和高效的模型。此外,LoRA在多模态学习、迁移学习以及模型可解释性方面的潜力也值得期待。
LoRA技术在AI模型压缩和边缘设备应用上的发展前景广阔。它不仅为当前的AI技术带来了新的可能性,也为未来的智能世界奠定了坚实的基础。随着技术的不断发展,我们有理由相信,LoRA将在推动人工智能走向更加智能化、高效化和广泛化方面发挥重要作用。

最新发布

热门推荐



